Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
EPOCH AI
현재 추세가 계속된다면, 언어 모델들은 2026년에서 2032년 사이에 이 데이터를 완전히 사용할 것으로 예상하는 연구 결과. 따라서 2030년 이후에는 새로운 방식의 혁신이 없다면 꾸준한 성장이 이루어지기 어려울 수도 있다고 이야기함
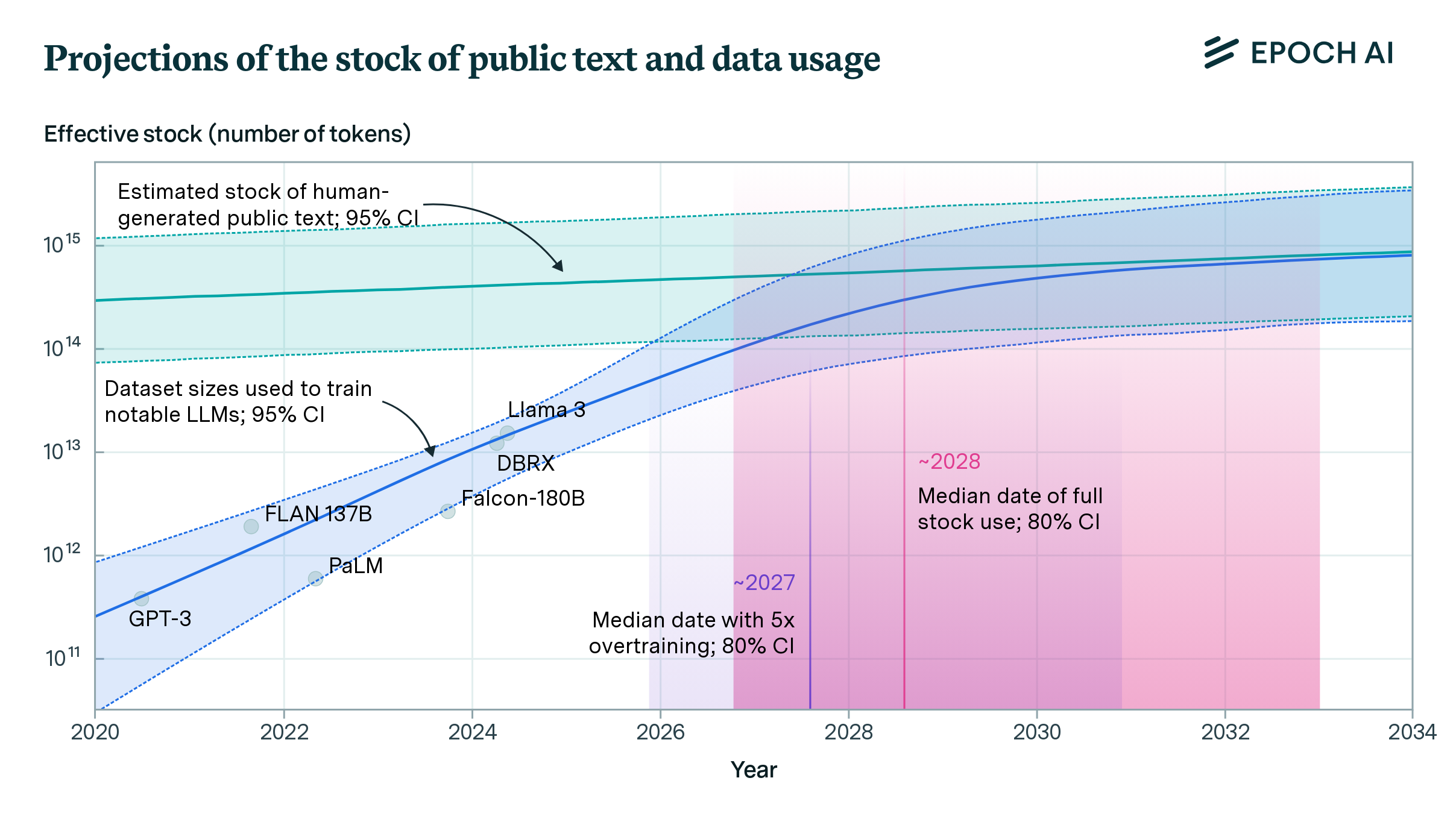
우리는 인간이 생성한 공개 텍스트 데이터의 총량을 약 300조 토큰으로 추정합니다. 이 추정치는 훈련에 사용할 수 있을 만큼 충분히 고품질인 데이터만 포함하며, 여러 차례 훈련에 사용할 가능성을 고려한 것입니다.
데이터의 총량을 추정한 후, 이 데이터가 언제 완전히 사용될지를 예측합니다. 우리는 데이터셋 크기의 역사적 성장률을 단순히 외삽하는 모델과 훈련 계산량 성장을 예측하고 이에 상응하는 데이터셋 크기를 도출하는 모델을 개발했습니다. 우리의 종합적인 예측에 따르면, 데이터는 2026년에서 2032년 사이에 완전히 사용될 것입니다.
답글 남기기