넷플릭스가 시청여부를 신경쓰지 않고 흘려보내는 시청을 내보낸다는 주장. 그런데 원래 TV의 역사를 보면 그러지 않았던가?
“여러 각본가들의 말에 따르면, 넷플릭스 임원들이 자주 주는 피드백 중 하나가 ‘시청자들이 프로그램을 배경으로 틀어놓고 볼 때도 흐름을 따라갈 수 있도록, 등장인물이 자기 동작을 입으로 설명하게 하라’는 것이다.”
넷플릭스가 시청여부를 신경쓰지 않고 흘려보내는 시청을 내보낸다는 주장. 그런데 원래 TV의 역사를 보면 그러지 않았던가?
“여러 각본가들의 말에 따르면, 넷플릭스 임원들이 자주 주는 피드백 중 하나가 ‘시청자들이 프로그램을 배경으로 틀어놓고 볼 때도 흐름을 따라갈 수 있도록, 등장인물이 자기 동작을 입으로 설명하게 하라’는 것이다.”
FCC Officially Opens Door to Mass Broadcast Deregulation
Radio Ink
- 비용-편익 분석: FCC는 특정 규제가 기업에 편익보다 더 많은 비용을 부과하는지, 그리고 이런 규정을 폐지하거나 수정하면 더 나은 경제적 결과로 이어질 수 있는지 조사하고 있습니다.
- 시장 및 기술 변화: 디지털 통신, 광대역, 방송이 급속히 발전함에 따라 FCC는 오래되었거나 불필요한 규칙을 파악하려고 노력합니다.
- 진입 장벽: 위원회는 규제가 소규모 기업에 과도한 부담을 주어 경쟁과 혁신을 제한하는지 분석하고 있습니다.
- 법률 및 헌법적 우려: FCC는 일부 규정이 최근의 사법 판결과 충돌하는지 여부를 고려하고 있습니다. 여기에는 이전에 기관에 법령 해석에 있어 상당한 여유를 부여했던 Chevron 의 존중 프레임워크를 뒤집은 대법원의 로퍼 브라이트 판결 이 포함됩니다.
- 규제 중복: 해당 기관은 또한 기존 FCC 규정이 보다 광범위한 연방, 주 또는 업계 자체 규제 조치와 중복되어 불필요한 규정 준수 부담을 초래할 가능성이 있는지도 검토하고 있습니다.
구체적 내용은 없지만 나중에 결과를 찾아봐야겠다.
How the U.S. Public and AI Experts View Artificial Intelligence
Pew Research
일반 대중에게 적합한 인터페이스가 아닐수 있다는 생각
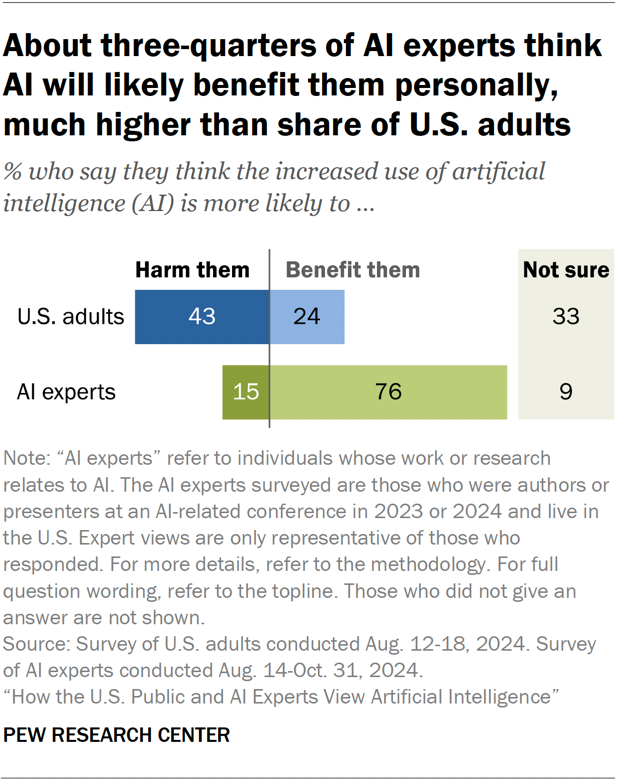
미국 성인보다 AI가 개인적으로 유익하다고 생각하는 전문가의 비율이 더 높습니다. 설문조사에 참여한 전문가 중 훨씬 더 많은 수(76%)가 이러한 기술이 자신에게 해(15%)가 되기보다는 유익할 것이라고 생각합니다.
대중은 AI가 자신에게 도움이 될 것이라고 생각하는 비율(43%)이 도움이 될 것이라고 생각하는 비율(24%)보다 훨씬 높습니다. 하지만 3분의 1은 확신하지 못한다고 답했습니다.
People are using Google’s new AI model to remove watermarks from images
TechCrunch
지난주, 구글은 제미니 2.0 플래시 모델의 이미지 생성 기능에 대한 접근성을 확대했습니다. 이 기능을 통해 제미니는 이미지 콘텐츠를 자체적으로 생성하고 편집할 수 있습니다. 모든 면에서 강력한 기능 입니다 . 하지만 몇 가지 단점도 있는 것 같습니다. 제미니 2.0 플래시는 유명인 과 저작권이 있는 캐릭터를 묘사한 이미지를 아무런 문제없이 생성할 수 있으며, 앞서 언급했듯이 기존 사진의 워터마크도 제거합니다.
AI middleware
Benedict Evans
첫째, 매우 다양하고 복잡한 소프트웨어를 표준화된 범용 계층으로 추상화하려고 하는데, 이는 ‘최소공약수’ 문제를 야기합니다. 미들웨어는 기반 도구가 생성하는 모든 기능을 지원할 수 없습니다(스티브 잡스의 ‘플래시에 대한 메모’ 참조). 둘째, Instacart가 왜 다른 회사의 수조 달러 규모 기업을 위한 단순한 API 호출이 되고 싶어 할까요? Instacart는 광고로 모든 수익을 창출하고, Uber는 검은색 승용차와 구독 상품을 판매하고 싶어 하며, Salesforce는 새로운 LLM 도구를 사용하기를 원합니다. 다른 누군가가 사용자 경험을 통제하고 고객을 소유하는 것을 원하지 않기 때문입니다.
스티브 잡스는 플래시와 관련해 Flash는 너무 복잡하고, 배터리를 소모하며, 보안 문제도 많고, 터치 인터페이스에도 맞지 않는다. 그리고 Flash 같은 미들웨어는 개발자가 플랫폼의 고급 기능을 쓰지 못하게 만든다는 요지로 말했었다. 너무 오래 전 이야기. 요즘 사람들은 플래시를 기억하기는 할까?
State of Work-Life Balance in Journalism 2025
MuchRack
언젠가 인용했던 자료인데 저장할 용도
- 언론인들 사이에서는 여전히 번아웃 현상이 심각합니다. 50%가 작년에 그만두는 것을 고려했습니다 .
- 61%는 업무 특성상 스트레스가 많음에도 불구하고 직장에서 정신 건강 서비스를 전혀 제공하지 않는다고 답했습니다.
- 기자들은 정신 건강 지원 , 더 나은 보상 , 더 많은 직원 , 하이브리드/원격 근무가 회사가 일과 삶의 균형을 개선할 수 있는 몇 가지 주요 방법이라고 말합니다 .
- 언론인의 38%는 직업 불안정과 업계 불안정을 이유로 지난해 정신 건강이 악화되었다고 보고했습니다.
Senators Accuse Google, Amazon, and Others of Monetizing Site That Hosts Child Abuse Content
Adweek
주요 광고기술 업체들이 아동 성학대 자료(CSAM)를 호스팅하는 웹사이트에 광고를 게재하여 의도치 않게 범죄에 자금을 지원하고 있다는 점에 대해 강력한 우려를 표하며 조사에 나섰다.
Google과 같은 디지털 광고주 네트워크가 그러한 활동을 호스팅하는 것으로 알려진 웹사이트에 광고를 게재하는 경우, 그들은 실제로 범죄 활동을 영속시키고 우리 아이들에게 돌이킬 수 없는 피해를 입히는 자금 흐름을 만들어냈습니다.
이러한 결과를 이끈 보고서는 여기(Adalytics)
YouTube TV, Wiz, and Why Monopolies Buy Innovation
Stratechery
과거에는 TV 시청자가 셋톱박스의 채널 가이드를 통해 하나의 인터페이스에서 모든 방송을 탐색할 수 있었지만, 스트리밍 시대가 되면서 스포츠·드라마·영화가 각기 다른 앱과 구독 서비스로 분산되었다. 이용자 입장에서는 시청할 콘텐츠를 찾는 것 자체가 번거로운 작업이 되었다. 유튜브는 분산된 시청 환경 속에서 모든 콘텐츠를 통합하는 플랫폼(aggregator)이 되려는 전략을 세우고 있다.
특히 애플과 아마존과는 대조적으로 다른 스트리밍 서비스가 빠져 있었습니다. 하지만 프라임타임 채널은 Apple TV 앱 스토어나 Amazon 프라임 비디오 마켓플레이스에 대한 YouTube만의 대안을 구축하려는 시도임이 분명합니다. 지난 달에 언급했듯이 YouTube가 NFL 선데이 티켓에 사치스러운 투자를 한 것은 다른 스트리밍 서비스를 설득하기 위한 의도와 노력의 표현이라고 생각합니다. 이상적인 미래는 스트리밍이든, 선형이든, 사용자 제작이든 모든 동영상 시대의 선두주자가 YouTube가 되는 것입니다(The idealized future is one where YouTube is the front-door of all video period, whether that be streaming, linear, or user-generated.).
미국에서 유튜브가 TV에서의 시청 시간이 모바일을 넘어서면서 격렬해진 논쟁에 관해 이야기하는 글. 유튜브가 전 세계에서 총 얼마만큼의 시청 시간을 생성하며, Netflix, Meta, Spotify, Snap 등과 비교해 얼마나 잘 수익화되고 있을까. 이 글에서는 유튜브의 1,000 시청 시간당 수익(RPMVH)을 41달러, 넷플릭스의 경우 190달러에 달한다고 본다.
두 플랫폼 간의 차이는 여러 요인에서 기인합니다. 우선, 많은 유튜브 동영상은 광고 없이도 오랜 시청 시간을 생성합니다(예를 들어, 게임을 하는 동안 다른 게임 플레이 영상을 보는 십대 아들이 있다면 이해가 되실 겁니다). 또한, 상당 부분의 시청 시간은 낮은 CPM을 가진 시장에서 발생합니다. 반면, Netflix의 대부분 시청은 월 구독료를 지불하는 사용자들이 TV 화면에서 시청합니다.
광고 수익이 본질적으로 낮은 RPMVH를 초래하는가 하면, Meta가 반대 사례를 제시합니다. Meta는 전체 앱 수익의 99%를 광고로부터 얻으면서도 1,000 시청 시간당 200달러 이상의 수익을 기록, 전 세계적으로 추적한 대형 플랫폼 중 시청 시간당 가장 높은 수익을 올리고 있습니다.
Thoughts on how Operator will play out
Steven Sinofsky
컴퓨터 사용 기능이 가질 수 있는 문제. 신원대행, 오류, 호환성 등 문제가 있을 것으로 예상. 하지만 자동화를 위한 생태계가 발전한다면 자동화를 위한 API를 제공하거나, 고려한 디자인으로 변화할 수도 있을 것이라 말한다. 그럼에도 (인간)이용자의 인게이지먼트가 중요한 앱들은 차단할 것이라 예상.
첫째, 모든 실수는 자신의 실수입니다. 그리고 실수한 것처럼 가치 있는 대부분의 작업에는 실행 취소 버튼이 없습니다.
둘째, 오늘날 자동화할 가치가 있는 앱은 운영자가 의도적으로 Chrome을 시뮬레이션하거나 더 교묘한 작업을 하지 않는 한 이런 종류의 로그인 세션을 거의 확실하게 비활성화할 것입니다. 주로 첫 번째 문제와 앱이 자동화가 잘못되는 것을 원하지 않기 때문입니다. 또한 앱, 특히 사용량에 따라 달라지는 앱이 자동화에 항상 저항해 온 것과 같은 이유, 즉 사용자의 흐름 중간에 끼어들어 더 많은 선택과 옵션, 방해 요소를 제공하고자 하는 이유도 있습니다. 그 외에도 화면 읽기/스크래핑/마우스 추적 자동화가 항상 실패했던 이유와 동일한 이유, 즉 앱이 변화하고 그 변화를 따라잡는 것이 불가능하다는 점 등 여러 가지 이유가 있습니다. 스크립트가 깨집니다.