Auto-GPT 활용하여 자체 코드를 작성하고 스크립트를 실행하는 사례. 이를 통해 디버깅도 가능하다. GPT를 활용하는 프로젝트가 더욱 다양해질 것 같고, 이를 활용하는 아이디어도 고민해볼만 하지 않을까.
[작성자:] haeyeop
-
LLM학습에 사용된 웹사이트
Inside the secret list of websites that make AI like ChatGPT sound smart
By Kevin Schaul, Szu Yu Chen and Nitasha Tiku, WP웹이 만들어진 이후 30여년 이상 수많은 이용자가 데이터 생산에 참여하고 무료로 공유했기에 지금과 같은 인공지능 모델이 가능할 수 있었다. 하지만 이제는 LLM이 인터넷인 연결되는 모델 전반을 바꾸어놓고 있는지 모른다.
캐나다 온라인 뉴스법이 현재대로 통과(플랫폼이 뉴스 퍼블리셔에게 콘텐츠 비용을 지불하도록 하는 규정)된다면 페이스북은 뉴스 콘텐츠 제공을 중단한다고 말했었다. 이러한 형태의 규정은 매우 이상하다. 입장을 바꿔본다면 언론사가 식당 리뷰 기사를 작성하면 식당에 돈을 지불해야한다는 것과 비슷하다.
스택오버플로우와 레딧은 LLM 학습에 사용된 데이터와 관련해 트레이닝 비용을 청구할 것이라고 밝혔다. 과연 LLM 시대에 콘텐츠 소유권은 누가 가지게 될 것인가? 어떤 방식의 배포가 이루어질 수 있는 것일까? 사실은 이러한 질문이 정당한 것인지도 아직 확신하기 어렵다.
워싱턴 포스트는 이와 관련해 인공지능 챗봇 학습에 사용하는 데이터 세트 중 하나인 구글의 C4 (Colossal Clean Crawled Corpus) 데이터셋을 분석했다. 데이터셋은 140억개 단어로 이루어져 있으며, 웹페이지, 뉴스, 책, 위키피디아와 같은 다양한 소스를 수집했다. 가장 많은 데이터를 제공한 사이트는 구글 페이턴트, 위키피디아, 스크립드였다.
전 세계에서 발행된 특허의 텍스트를 제공하는 patents.google.com이 1위, 무료 온라인 백과사전인 위키피디아.org가 2위, 구독 전용 디지털 라이브러리인 scribd.com이 3위를 차지했습니다.
카테고리에서 뉴스 및 미디어는 3위였으며, 신뢰도가 낮은 언론 매체도 순위 내에서 발견되었다.
뉴스 및 미디어 카테고리는 전체 카테고리에서 3위를 차지했습니다. 하지만 상위 10개 사이트 중 절반이 뉴스 매체였습니다. nytimes.com이 4위, latimes.com이 6위, theguardian.com이 7위, forbes.com이 8위, huffpost.com이 9위였습니다. (워싱턴포스트닷컴이 11위로 뒤를 이었습니다.) 예술가 및 크리에이터와 마찬가지로 일부 언론사들은 기술 기업이 허가나 보상 없이 콘텐츠를 사용하는 것에 대해 비판했습니다.
한편, 뉴스가드의 독립적인 신뢰도 평가에서 낮은 순위를 차지한 언론 매체도 몇 개 발견되었습니다: 러시아 국영 선전 사이트인 RT.com(65위), 극우 뉴스와 의견으로 잘 알려진 브레이트바트닷컴(159위), 백인 우월주의와 연관된 반이민 사이트인 vdare.com(993위)이 그 예입니다.
C4는 2019년 4월을 시점으로 이루어진 웹스크레이핑으로 “평판이 좋은 사이트의 우선 순위를 정하려고 했지만, 라이선스가 있거나 저작권이 있는 콘텐츠를 피하려고 하지 않는다”라고 말했다.
LLM으로 인해 캐나다 언론사의 이상한 것처럼 보이던 모델이 그럴듯한 것처럼 보이게 될 수 있는 시대가 되는거 아닌가. 인공지능 콘텐츠의 권리에 대해서 어디까지가 누구의 소유이고 비용 지불은 어떻게 가능해질지 점차 민감한 문제가 될 것이고 많은 변화가 있을 것이다.
-
프롬프트 엔지니어링 테크닉
언어모델에서 좋은 결과물을 얻기 위해 프롬프트를 잘 쓰는 방법에 대해서 이야기가 많은데, 보다보면 이게 새로운 개발언어지 자연어인가 싶은 느낌이 들 때가 있다.
문단을 읽고 사실적 주장을 추출한 다음 검색 엔진 결과를 사용하여 사실을 확인합니다.
—
문단
John Smith는 Lucy Smith와 결혼했습니다. 그들은 다섯 자녀를 두고 있으며 그는 Microsoft에서 소프트웨어 엔지니어로 일하고 있습니다. 팩트체크를 하려면 어떤 검색어를 써야 할까요?
—
사실적 주장
– John Smith는 Lucy Smith와 결혼했습니다.
– John과 Lucy에게는 다섯 자녀가 있습니다.
– John은 Microsoft에서 소프트웨어 엔지니어로 일하고 있습니다.
—
다음은 위의 주장을 조사하기 위해 발행된 다양한 검색 쿼리입니다.
검색 쿼리
– John Smith는 결혼했습니다. Lucy Smith에게
– John Smith 자녀 수
– John Smith 소프트웨어 엔지니어 Microsoft
—
다음은 검색 결과의 일부입니다.
스니펫:
[1] … John Smith의 결혼식은 2012년 9월 25일이었습니다 …
[2] … John Smith는 그의 아내 Lucy와 함께 파티에 참석했습니다.
[3]John은 다음과 같은 축구 경기에 동행했습니다. 그의 두 딸과 세 아들
[4] … Microsoft에서 10년을 보낸 후 Smith는 자신의 스타트업인 Tailspin Toys를 설립했습니다.
[5] John M은 마을 대장장이이며 Fiona와 결혼했습니다. 그들에게는 Lucy라는 딸이 있습니다
. —
스니펫이 주어지면 위의 각 사실 주장을 사실 확인하십시오.개발 언어 배우기보다 어려운게 사람과 커뮤니케이션하는 부분이라고 한 말이 생각난다.
-
인공지능 학습과 데이터
A Photographer Tried to Get His Photos Removed from an AI Dataset. He Got an Invoice Instead.
Motherboard, by Chloe Xiang독일의 한 스톡 사진작가가 AI 학습용 LAION 데이터 세트에서 자신의 사진을 삭제하려고 시도했는데 오히려 변호사는 부당한 저작권 청구로 979달러를 지불해야 한다는 답변을 받았다는 기사.
인공지능 학습과 저작권에 대한 논쟁이 점차 심해질 것이고, Zarya of the Dawn 같은 코믹스 저작권 관련 판결이 논쟁이 되기도 한 바 있다. 과연 어떤 방식의 접근이 좋은지 명확하게 판단하기는 어렵지만 Benedict Evans가 과거에 쓴 데이터에 관한 글 일부를 생각해볼만하다.
기술은 내러티브로 가득 차 있지만 가장 시끄러운 것 중 하나는 ‘데이터’라는 것입니다. AI는 미래입니다. 데이터에 관한 모든 것입니다. 데이터는 미래입니다. 우리는 그것을 소유하고 아마도 지불해야 하며 국가는 데이터 전략과 데이터 주권이 필요합니다. 데이터는 새로운 석유입니다! 이것은 대부분 넌센스입니다. ‘데이터’와 같은 것은 존재하지 않으며, 가치가 없으며 어쨌든 실제로 귀하의 소유가 아닙니다.
2017년 이코노미스트 컬럼은 데이터를 석유에 비유하며 자원으로 이야기했으나 데이터는 석유 같은 자원이 아니라는 이야기. 특정한 맥락에서 특정한 목적을 가지고 있을 때에만 가치를 가지기 때문에 석유와 같은 자원으로 비유하는 것은 적절하지 않다는 것이다(나도 과거에 데이터를 모을 때 같이 협업하던 분이 데이터가 아니라 거대한 쓰레기라는 말을 한 게 생각난다).
물론 일부 유형의 데이터에서 문제가 될 수 있는 부분들도 있으나, 우리가 이런 논의를 위해서는 어떤 종류의 데이터에 어떤 크레딧을 줄 수 있는지 분리해서 생각하는 것이 필요하지 않을지.
-
모질라의 Fakespot 인수
Mozilla buys Fakespot, a startup that identifies fake reviews, to bring shopping tools to Firefox
모질라는 가짜 리뷰를 식별하는데 도움을 주는 브라우저 플러그인 Fakespot을 인수.
2016년에 설립된 뉴욕에 기반을 둔 Fakespot은 AI 및 머신 러닝 시스템을 사용하여 리뷰 간의 패턴과 유사성을 감지하여 기만적일 가능성이 가장 높은 리뷰를 표시합니다. Fakespot은 소비자가 구매 시 더 많은 정보에 입각한 결정을 내릴 수 있도록 제품 리뷰에 등급이나 등급을 부여합니다. 이 회사의 웹사이트와 브라우저 확장 프로그램의 목표는 검색 엔진에서 기만적인 리뷰가 인위적으로 제품 순위를 부풀릴 수 있는 위치를 사용자가 빠르게 확인할 수 있는 기능을 제공하는 것입니다.
아마존에 ChatGPT를 활용하여 가짜 리뷰를 작성하는 일이 증가함에 따라(As an AI language model…) 이런 수요가 높아지겠지만 정말 식별이 가능한지도 사실 잘 모르겠다.
-
아마존의 ChatGPT 활용 도서
He wrote a book on a rare subject. Then a ChatGPT replica appeared on Amazon.
WP, by Will Oremus생성 인공지능으로 인해 쓰레기가 넘쳐나는 웹이 되지 않을까 생각했는데 생각보다도 빠르게 진행되고 있는 모습 아닌가 싶다. 사례는 ChatGPT를 활용하여 만든 도서의 복제본이 아마존에서 판매되고 있다는 사실을 언급하고 있다.
콘텐츠 생산에는 커다란 진입 장벽이 있었다. 인터넷은 유통 측면에서 문제를 해결하며 무한한 수요를 만들었으나 공급은 그렇지 않았기 때문에 콘텐츠가 왕이라는 말까지도 있었다. 하지만 생성 인공지능은 이러한 공급의 문제를 해결해 줄 것처럼 보였다.
하지만 마치 폭등하는 주가차트처럼 올라갔다가 다시 꺼지는 상황이 발생하지 않을지. 네이버 웹툰의 영업 실적을 보면 어두운 전망을 나타내는데, 마치 아타리 쇼크를 떠올리게 하는 상황의 전조는 아닌지. 콘텐츠 생산의 기술적 어려움은 낮아지고 있는 것처럼 보이지만 정말 볼만한 콘텐츠란 언제나 희소하다.
-
OTT서비스 이탈률
Price Point 031: TV Questions Asked of TV Companies
Roy PriceOTT시장 경쟁상황 전반에 대한 요약이 잘 되어 있는 글. 2022년 6월 기준으로 미국 스트리밍 서비스 시청은 34.8%로 케이블 이용(34.4%)을 넘어섰으나 이러한 시장을 8~9개 사업자가 나누어가지는 형태로 구성되어 있다. 모든 스트리밍 서비스 중 1위는 유튜브, 구독 기반 서비스 중에서는 넷플릭스가 선두.
문제는 서비스 해지율(churn rate)에 대한 것으로, 이탈률이 높아질수록 새로운 고객을 유치하기 위해서 개별 업체가 투자해야하는 비용이 증가하게 된다는 것이다. 이를 줄이기 위한 전략으로 언급되는 것은 다음과 같다.
이를 개선하기 위해 사용할 수 있는 수단으로는 (a) 축구 시즌이나 텐트폴 타이틀과 같이 고객에게 항상 기대할 만한 요소를 제공하여 해지율 자체를 낮추는 것, (b) 계절성이 덜한 다른 구독 서비스(예: Prime 또는 Netflix와 Spotify를 하나로 묶으면 어떨까요?)와 서비스를 번들링하는 것, (c) 다른 가치 있는 구독 서비스와 번들링하는 것, (d) 다른 구독 서비스와 번들링하는 것 등이 있습니다.), (c) 소셜 네트워크나 채팅과 같은 가치 있는 서비스와 구독 서비스를 번들로 제공(BiliBili), (d) 아이덴티티를 통해 브랜드 충성도를 창출(뉴요커 토트백, A24 범퍼 스티커), (e) 구독을 연간으로 설정, (f) 좋은 소문(“입소문”)을 들었거나 홍보를 본 고객(“획득된 미디어”)을 “무료로” 유치하여 신규 고객당 비용을 절감하는 방법 등 다양한 방법이 있을 수 있습니다. 신규 고객당 비용을 80달러에서 50달러로 낮출 수 있다면 이는 큰 도움이 됩니다.[expand title=eng]
Levers you might pull to make this a little better include (a) reducing the churn rate itself by always giving customers something to look forward to such as football season or a tent pole title, (b) bundling your service with other less seasonal subscriptions (like Prime, or — what if Netflix and Spotify were one?), (c) bundle your subscription service with a valued service such as a social network and chat (BiliBili), (d) create brand loyalty through identity (New Yorker totes, A24 bumper stickers), (e) making the subscription annual, and (f) reducing the cost per new customer by attracting customers “for free” because they’ve been hearing good things (“word of mouth”) or saw some publicity (“earned media”). If you can cut your cost per new customer down from $80 to $50, it’s a lifesaver. [/expand]이를 바탕으로 각 서비스 업체에 대하나 간략한 현황과 방향에 대한 정리가 되어 있고, 다음과 같이 시장 상황을 유형화했다.
- Leader: Netflix
- Tier 2: Prime, Hulu, Disney+
- Tier3: Max, Peacock, Paramount
- Tier4: Apple
-
ChatGPT와 대학과제평가
Professor Flunks All His Students After ChatGPT Falsely Claims It Wrote Their Papers
By Miles Klee사건 경과가 어떻게 진행되고 진실인지 아닌지 여부를 이후에 별도로 확인하지는 않았지만, 그 이후 별다른 정정보도가 붙어있지 않아서 기록용으로 남기는 기사. 수업시간에도 언급한 바 있으나 기술에 대한 이해도로 인해 이상한 결론으로 이끌게 된 사례
그는 각 논문을 두 번씩 테스트했다고 말하며 “[ChatGPT]에 학생들의 답변을 복사하여 붙여넣으면 프로그램이 내용을 생성했는지 알려줍니다.”라고 썼습니다. 그는 이론적으로 졸업 자격에 위협이 될 수 있는 낙제점을 피하기 위해 학생들에게 보충 과제를 제안했습니다.
한 가지 문제가 있습니다. ChatGPT는 그런 식으로 작동하지 않습니다. 이 봇은 AI가 작성한 자료나 심지어 자체적으로 생성한 자료를 감지하도록 만들어지지 않았으며, 때때로 피해를 주는 잘못된 정보를 방출하는 것으로 알려져 있습니다. ChatGPT는 약간의 자극만 주면 범죄와 처벌과 같은 유명 소설의 구절을 작성했다고 주장하기도 합니다. 교육자는 학생들이 과제를 스스로 완료했는지 평가할 수 있는 다양하고 효과적인 AI 및 표절 감지 도구 중에서 선택할 수 있으며, 여기에는 Winston AI 및 Content at Scale이 포함됩니다. 그리고 봇이 작성한 텍스트인지 여부를 판별하는 OpenAI의 자체 도구는 기업에 기술 리소스를 추천하는 디지털 마케팅 대행사에 의해 “정확도가 떨어진다”는 평가를 받았습니다.[expand title=eng]“I copy and paste your responses in [ChatGPT] and [it] will tell me if the program generated the content,” he wrote, saying he had tested each paper twice. He offered the class a makeup assignment to avoid the failing grade — which could otherwise, in theory, threaten their graduation status.
There’s just one problem: ChatGPT doesn’t work that way. The bot isn’t made to detect material composed by AI — or even material produced by itself — and is known to sometimes emit damaging misinformation. With very little prodding, ChatGPT will even claim to have written passages from famous novels such as Crime and Punishment. Educators can choose among a wide variety of effective AI and plagiarism detection tools to assess whether students have completed assignments themselves, including Winston AI and Content at Scale; ChatGPT is not among them. And OpenAI’s own tool for determining whether a text was written by a bot has been judged “not very accurate” by a digital marketing agency that recommends tech resources to businesses.[/expand] -
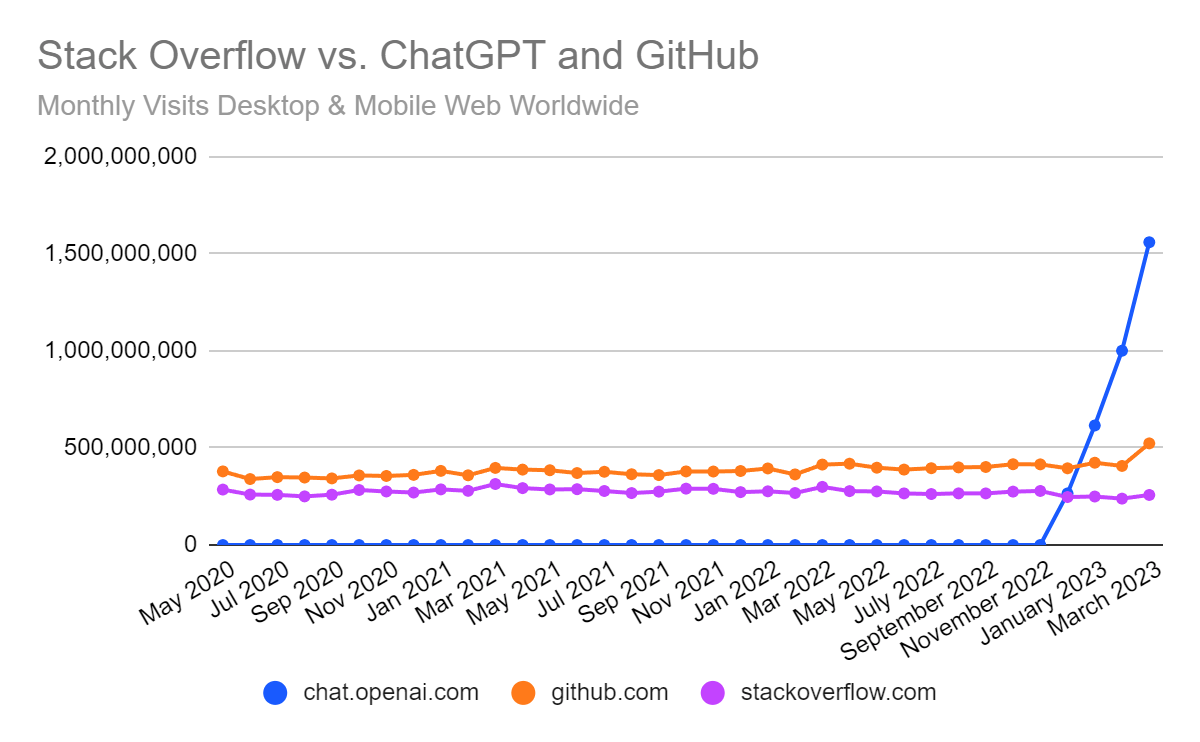
GPT와 스택오버플로우 트래픽
Stack Overflow is ChatGPT Casualty: Traffic Down 14% in March
Smiliarweb 통계를 보면 스택오버플로우 트래픽은 큰 폭으로 감소. 인과관계를 명확하게 말할 수 있는지는 모르겠지만 튜토리얼과 함께 코드 샘플을 보여주는 언어모델이 스택 오버 플로우를 죽일 것이라는 예측이 있었다. 하지만 실제 ChatGPT 콘텐츠를 스택오버플로우에 게시하는 것은 금지. 답변이 너무 부정확하기 때문인데 이와 관련해서는 많은 사례들이 이야기되고 있다. 사이트는 깃허브 성장에 관해서도 언급한다(나중에 필요한 경우 참고).